Method Overview
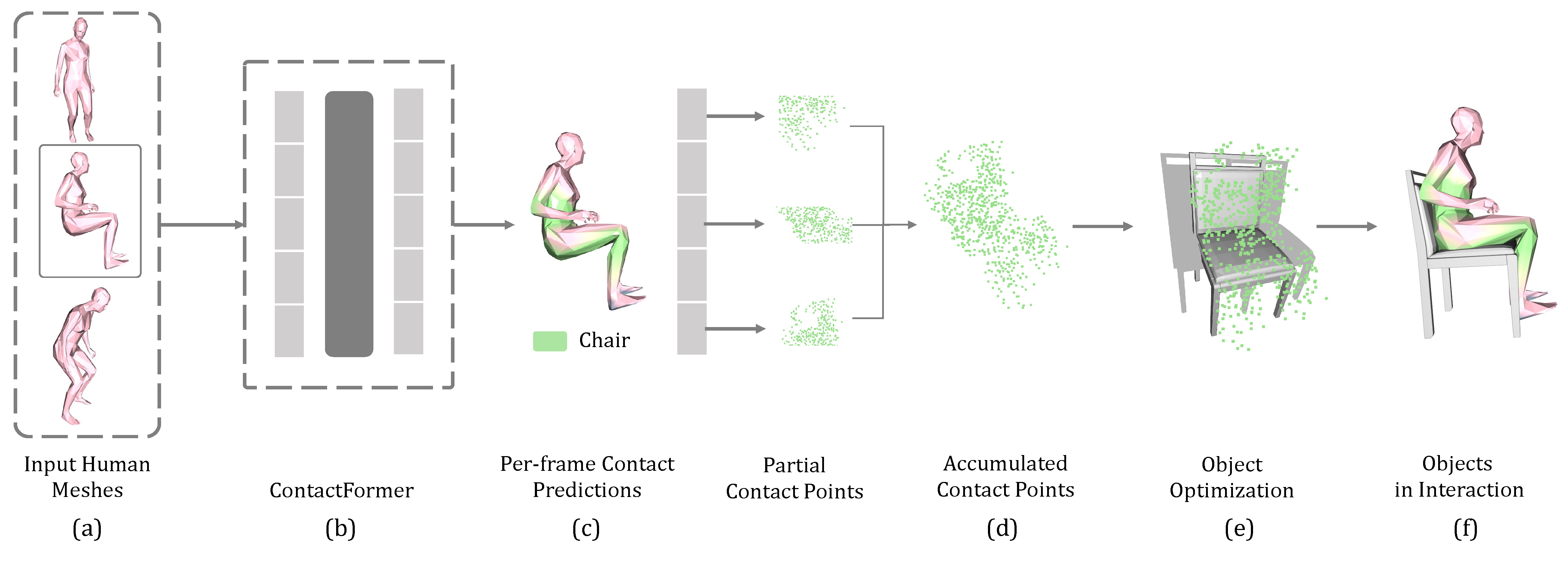
The overview of SUMMON: (a) an input sequence of human body meshes interacting with a scene, (b) the ContactFormer that predicts per-frame contact labels, (c) per-frame contact predictions, (d) estimated contact points, (e) synthesized objects, and (f) objects in interaction.
Experiment Results
Diverse scene generation
By leveraging predicted contact semantic labels, SUMMON can synthesize diverse plausible scenes from a human motion sequence. Hence it has the potential to generate extensive human-scene interaction data for the community.
Scene Completion
SUMMON further completes the scene by sampling and placing objects that are not in contact with humans.