Method Overview
Estimating 3D human motion from an egocentric video sequence is critical to human behavior understanding and applications in VR/AR. However, naively learning a mapping between egocentric videos and human motions is challenging, because the user's body is often unobserved by the front-facing camera placed on the head of the user. In addition, collecting large-scale, high-quality datasets with paired egocentric videos and 3D human motions requires accurate motion capture devices, which often limit the variety of scenes in the videos to lab-like environments.
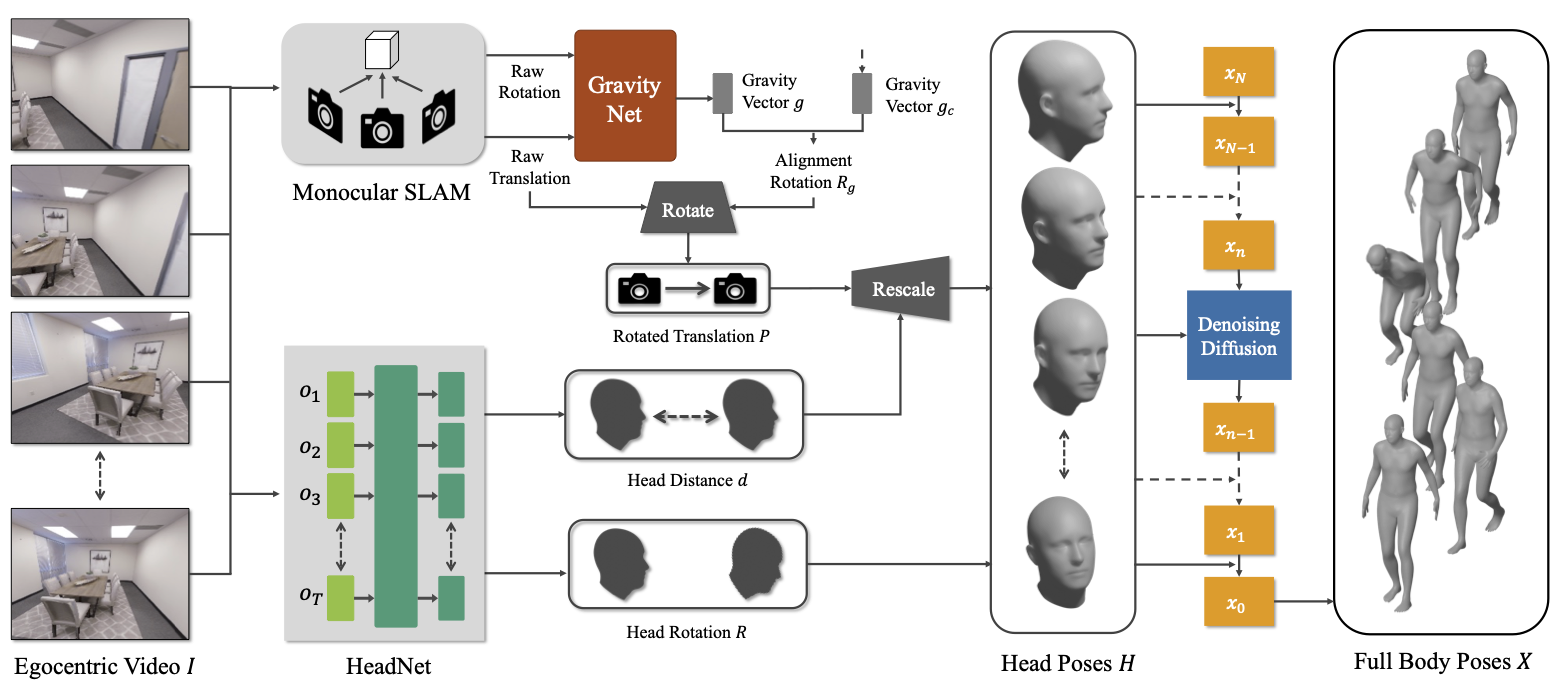
To eliminate the need for paired egocentric video and human motions, we propose a new method, Ego-Body Pose Estimation via Ego-Head Pose Estimation (EgoEgo), that decomposes the problem into two stages, connected by the head motion as an intermediate representation. EgoEgo first integrates SLAM and a learning approach to estimate accurate head motion. Then, taking the estimated head pose as input, it leverages conditional diffusion to generate multiple plausible full-body motions. This disentanglement of head and body pose eliminates the need for training datasets with paired egocentric videos and 3D human motion, enabling us to leverage large-scale egocentric video datasets and motion capture datasets separately.
Moreover, for systematic benchmarking, we develop a synthetic dataset, AMASS-Replica-Ego-Syn (ARES), with paired egocentric videos and human motion. On both ARES and real data, our EgoEgo model performs significantly better than the state-of-the-art.